# 大文件分片上传
# 实现思路
大文件分片上传,其思路就是把大文件拆分成一个个小文件单独进行上传,如果整个大文件一起上传会受制于http请求上传限制,而分片上传则可以通过多个http请求进行快速上传,每个请求独立完成,不用等待其他请求,等所有请求上传完成后告诉后端把所有上传文件整合成一个文件。
这其中后端主要提供两个接口,一个上传接口和一个合并接口,上传接口和我们之前的文件上传一样,把文件内容传给后端就行了,合并接口就是等所有分片文件上传完成,前端告诉后端把所有文件进行合并,合并成功告诉前端文件的存储路径。当然,最好还要提供一个文件上传验证接口,前端用来判断文件是否上传过。
而前端则需要对文件进行分片处理,hash值计算,分片上传,上传请求数量限制,上传进度计算,取消上传,文件重传秒传等,当然也要对文件上传的交互效果进行优化,比如显示文件大小、类型、上传大小、上传时间,取消上传,继续上传等。
这里介绍几个概念:
hash值计算:根据文件内容计算其唯一的md值,用于后端合并文件和验证文件。
断点续传:断点续传就是文件上传一半后取消上传了,如果再次上传此文件,已经上传的内容就不需要再上传一遍了,直接上传没有上传的。
文件秒传:文件秒传就是已经上传过的文件直接提示上传完成。
# 文件分片
文件切片很简单,就像截取数组一样截取文件,我们通过input或者上传组件获取文件File对象,然后通过while循环和slice方法对文件进行分片,放在数组中返回。
<template>
<div id="app">
<el-upload action="#" :auto-upload="false" :show-file-list="false" :on-change="handleChange">
<div class="upload-handle">上传文件</div>
</el-upload>
</div>
</template>
<script>
const CHUNK_SIZE = 2
export default {
name: 'App',
data() {
return {
fileData: null,
chunkList: [],
}
},
methods: {
// 上传
async handleChange(file) {
this.fileData = file.raw
console.log(this.fileData)
// 创建切片
const chunkList = this.createFileChunk(this.fileData, 2)
console.log('切片列表', chunkList)
},
/**
* @desc 生成切片文件
* @param {File} file 文件流数据
* @param {Number} size 切片大小默认2M
* */
createFileChunk(file, size = CHUNK_SIZE) {
const chunkList = []
// 切片大小
const chunkSize = size * 1024 * 1024
let sumSize = 0
if (chunkSize < file.size) {
while (sumSize < file.size) {
chunkList.push({
file: file.slice(sumSize, sumSize + chunkSize)
})
sumSize += chunkSize
}
} else {
chunkList.push({
file: file
})
}
return chunkList
}
}
}
</script>
# 计算hash值
在上传文件时,后端需要知道每个切片文件的唯一值来进行文件的合并和判断该文件是否上传,如果只靠名字或者唯一字符串是无法区分文件内容的,这时我们可以使用 spark-md5 插件,它可以根据文件内容计算出文件的 hash 值。
我们只需通过spark-md5计算整个文件唯一hash值,不用每个切片都计算,计算好整个文件的hash值后只需根据切片索引值在计算切片的hash值就可以了。
考虑到是上传的大文件,如果直接使用生成可能会导致页面卡死,所以我们使用 web-worker 在 worker 线程中单独计算 hash,不影响页面正常操作。在web-worker无法引入插件,所以我们直接去下载 spark-md5.min (opens new window) 的js文件,放在public目录下。并在public下创建一个worker线程js文件。当然,文件目录也不必放在public下。
// /public/hash.js
// 导入脚本
self.importScripts("/spark-md5.min.js");
// 接收传入进来的分片文件列表生成文件 hash
self.onmessage = e => {
const { fileChunkList } = e.data;
const spark = new self.SparkMD5.ArrayBuffer();
let percentage = 0;
let count = 0;
const loadNext = index => {
const reader = new FileReader();
reader.readAsArrayBuffer(fileChunkList[index].file);
reader.onload = e => {
count++;
spark.append(e.target.result);
if (count === fileChunkList.length) {
self.postMessage({
percentage: 100,
hash: spark.end()
});
self.close();
} else {
percentage += 100 / fileChunkList.length;
self.postMessage({
percentage
});
loadNext(count);
}
};
};
loadNext(0);
};
在 worker 线程中,利用 fileReader 读取每个切片的 ArrayBuffer 并不断传入 spark-md5 中,每计算完一个切片通过 postMessage 向主线程发送一个进度事件,全部完成后将最终的 hash 发送给主线程。
然后在主线程接收事件,获取文件的hash值。
<script>
export default {
name: 'App',
data() {
return {
fileData: null,
chunkList: [],
fileList: [],
requestList: [], // 上传切片请求列表
fileHash: '', // 文件唯一hash
}
},
methods: {
// 上传
async handleChange(file) {
this.fileData = file.raw
console.log(this.fileData)
// 创建切片
const chunkList = this.createFileChunk(this.fileData, 2)
console.log('切片列表', chunkList)
// 生成整个文件的hash值
this.fileHash = await this.calculateHash(chunkList)
},
// 计算文件的md5唯一hash值
calculateHash(fileChunkList) {
return new Promise(resolve => {
// 添加 worker 属性
this.workerInstance = new Worker('/hash.js')
this.workerInstance.postMessage({ fileChunkList })
this.workerInstance.onmessage = e => {
const { percentage, hash } = e.data
// this.hashPercentage = percentage
if (hash) {
resolve(hash)
}
}
})
}
}
}
</script>
# 请求封装
在上传前,考虑到后面的取消上传等功能,上传文件接口我们不使用第三方库,直接使用原生的XMLHttpRequest对象来封装请求。如果需要登录token可以通过header对象传入,其他参数都放在data参数中就可以了,这里onprogress是请求自带的callback函数,可以用来计算上传进度。
// 文件上传接口封装
uploadRequest({ index, url, method = 'post', data, headers = {} }) {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest()
xhr.upload.onprogress = this.uploadPercentage(index)
xhr.open(method, url)
Object.keys(headers).forEach(key => xhr.setRequestHeader(key, headers[key]))
xhr.send(data)
xhr.onload = e => {
resolve({
data: e.target.response
})
}
xhr.onerror = (err) => {
reject(err)
}
// 暴露当前 xhr 用于取消请求
this.fileList[index].xhr = xhr
})
},
# 分片上传
接口封装好后,就可以进行批量上传文件了,上传接口和以前的单个文件上传接口一样,我们循环分片列表进行上传,使用Promise.allSettled方法等待所有分片请求上传完成。
<script>
const CHUNK_SIZE = 2 * 1024 * 1024
export default {
name: 'App',
data() {
return {
fileData: null,
chunkList: [],
fileList: [],
requestList: [], // 上传切片请求列表
}
},
methods: {
// 上传
async handleChange(file) {
this.fileData = file.raw
console.log(this.fileData)
// 创建切片
const chunkList = this.createFileChunk(this.fileData, 2)
console.log('切片列表', chunkList)
// 生成整个文件的hash值
this.fileHash = await this.calculateHash(chunkList)
// 创建上传列表
this.fileList = chunkList.map((item, index) => {
const hash = `${this.fileHash}-${index}` // 根据文件hash生成切片hash
return {
fileHash: this.fileHash, // 唯一hash
chunk: item.file,
hash, // 为每个分片添加hash值
size: item.file.size,
// percentage: uploadedList.includes(hash) ? 100 : 0, // 分片进度条
index
}
})
// 批量上传,传入已上传列表
this.batchUploadChunk()
},
// 批量上传切片文件
async batchUploadChunk(uploadedList = []) {
console.log(uploadedList)
const requestList = []
// 过滤掉已上传的
const filterList = this.fileList.filter(item => !uploadedList.includes(item.hash))
// 创建formData批量请求
filterList.forEach((item, index) => {
// 创建formData
const formData = new FormData()
formData.append('chunk', item.chunk)
formData.append('fileHash', this.fileHash)
formData.append('hash', item.hash)
formData.append('filename', this.fileData.name)
const requestObj = this.request({
url: 'http://localhost:3003/upload',
data: formData,
// onProgress: this.createProgressHandler(index), // 计算进度条
requestList: this.requestList
})
requestList.push(requestObj)
})
console.log('请求列表', requestList)
// 发送所有切片
await Promise.allSettled(requestList)
// 合并切片
// 之前上传的切片数量 + 本次上传的切片数量 = 所有切片数量时合并切片
if (uploadedList.length + requestList.length === this.fileList.length) {
// const data = await this.mergeRequest()
// console.log('文件上传成功', data)
}
}
}
}
</script>
# 控制上传数量
上面切片上传是一下把所有文件都上传了,如果切片过多,请求过多也会造成浏览器响应缓慢、卡顿,所以,我们需要控制分片上传的数量,每次只能限制几个上传,这就涉及到一个知识点,如何控制浏览器请求并发数。
给定一个请求队列等待执行,我们如何通过一个函数控制其一个一个按照顺序执行,一个执行完了下一个才能继续执行,我们可以设置一个指针索引,指针指到哪个就执行哪个请求,然后执行完一个请求指针自动加一,这样请求完一个在执行请求就是下一个。
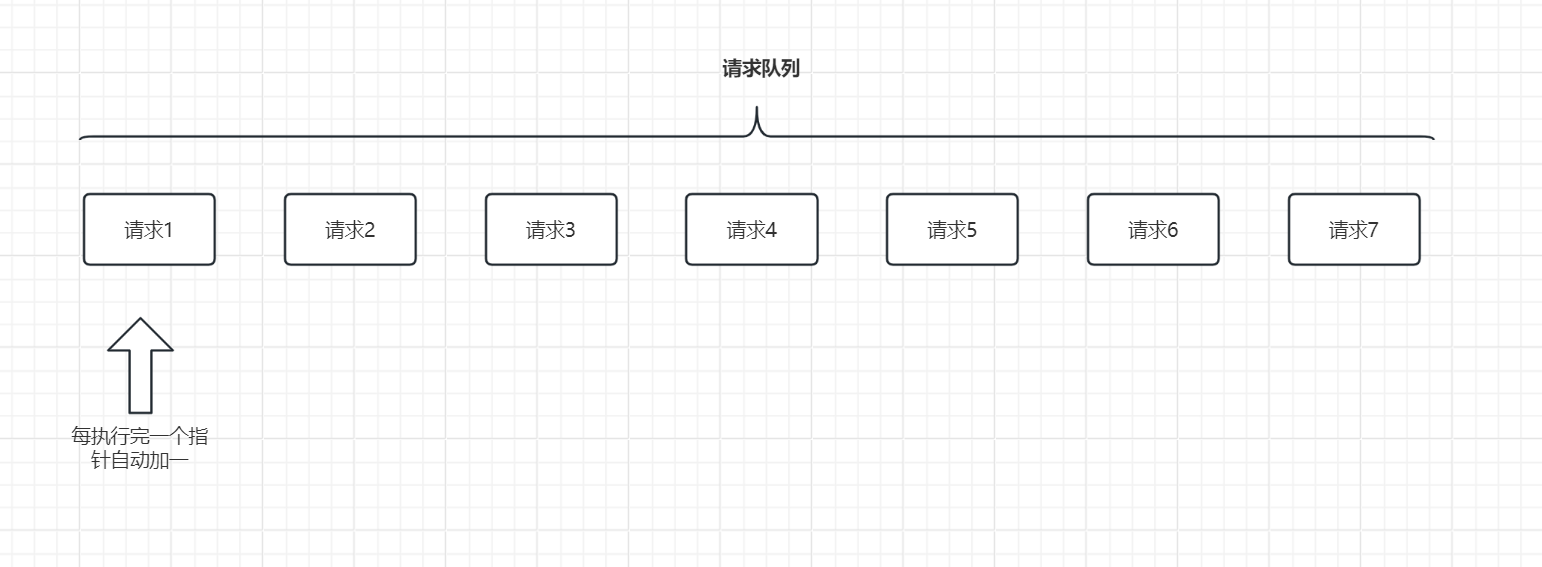
const requestList = [{}, {}, {}];
// 指针
let requestIndex = 0;
function request() {
let index = requestIndex;
requestIndex++;
// 调用接口
const data = requestList[index]
ajax({
url: 'xxxx',
data,
success: function() {
request()
}
})
}
// 并发一次
request();
// 并发两次
request();
request方法执行一次就是限制一个并发数,执行几次request方法就是限制几次并发请求,想一想是不是这个道理,不论我request方法刚开始执行几次,requestIndex指针一直都是递增的,执行5次就会触发5次回调继续递增。
/**
* @desc 限制最大并发请求
* @param {*} limit 最大请求数
* @param {*} requestList 请求列表
* */
function limitMaxRequest(limit, requestList) {
// 指针
let requestIndex = 0;
for (let index = 0; index < limit; index++) {
request()
}
// 请求回调
function request() {
let index = requestIndex;
requestIndex++;
// 调用接口
const data = requestList[index]
ajax({
url: 'xxxx',
data,
success: function() {
// 边界判断
if (requestIndex <= requestList.length - 1) {
request()
}
}
})
}
}
所以,在分片上传限制数量后,要重新改写上传逻辑。
// 上传文件
async handleChange(elFile) {
this.fileData = elFile.raw
console.log('文件对象', this.fileData)
// 创建切片
const chunkList = this.createFileChunk(this.fileData, this.chunkSize)
console.log('切片列表', chunkList)
// 生成整个文件的hash值
this.fileHash = await this.calculateHash(chunkList)
// 创建上传列表
this.fileList = chunkList.map((item, index) => {
const hash = `${this.fileHash}-${index}` // 根据文件hash生成切片hash
return {
fileHash: this.fileHash, // 唯一hash
size: item.file.size,
chunk: item.file,
hash,
name: hash,
index, // 当前索引
xhr: null, // 当前请求
}
})
// 批量上传
this.batchUploadChunk()
},
// 限制上传数量
batchUploadChunk() {
this.startUploadTime = Date.now()
// 限制最大请求数量
for (let index = 0; index < this.maxRequestNum; index++) {
this.handleUploadFile()
}
},
/**
* @desc 上传分片文件,并限制最大请求数量
* 1、定义全局索引指针requestIndex来执行哪个请求,每次请求确定下一个指针是哪个
* 在当前请求完成后执行下一个请求,这样指针一直可以自增
* 2、根据同时调用几次该接口就是限制最大请求数量
* @author changz
* */
async handleUploadFile() {
// 向父组件传递加载中状态
// this.$emit('update:getUpload', true)
const index = this.requestIndex
// 每次请求索引自增到下一个请求
this.requestIndex++
const item = this.fileList[index]
const formData = this.getFormData(item)
// 上传
const res = await this.uploadRequest({
index,
url: 'http://localhost:3003/upload',
data: formData
})
// 边界判断,如果请求索引小于请求最大值
if (this.requestIndex <= this.fileList.length - 1) {
// 每次执行完,不论失败还是成功继续执行下一个请求
this.handleUploadFile()
}
}
# 文件合并
所有分片上传好后,我们需要调用接口告诉后端进行合并,后端根据文件的唯一hash找到对应的分片进行合并文件,合好后即可把对应的分片进行删除。如上在分片上传完成后判断调用。
// 合并请求,告诉服务器文件发送完成
async mergeRequest() {
const chunkSize = this.chunkSize * 1024 * 1024
await this.request({
url: 'http://localhost:3003/merge',
headers: {
'content-type': 'application/json'
},
data: JSON.stringify({
size: chunkSize,
fileHash: this.fileHash,
filename: this.fileData.name
})
})
},
# 进度条计算
首先先计算每个分片的上传进度, 每个分片请求都有一个progress回调方法,此回调方法会返回请求上传量和总量,对比就可以算出分片上传进度。
// 更新单个接口上传进度
uploadPercentage(index) {
return (e) => {
// 当前上传进度
this.fileList[index].loaded = e.loaded
// 计算文件进度
this.fileList[index].percent = parseFloat(((e.loaded / e.total) * 100).toFixed(2))
}
},
整个文件的上传进度 = 每个分片大小 * 每个分片上传进度 的累加 / 总文件大小。
computed: {
// 计算总进度
uploadPercentage() {
if (!this.fileData || !this.fileList.length) return 0
const loaded = this.fileList.map(item => item.size * item.percentage).reduce((acc, cur) => acc + cur)
return parseInt((loaded / this.fileData.size).toFixed(2))
}
},
# 取消上传
取消上传要使用接口的取消请求abort方法,我们在上传分片请求的时候,记录对应的请求,然后在取消时,如果没有上传完就调用请求的abort方法进行取消。
// 暂停上传
handlePause() {
this.fileList.forEach(item => {
// 取消上传
item.xhr?.abort()
})
this.requestIndex = 0
this.fileList = []
},
# 文件秒传
当上传过的文件再次上传时,后端提供一个验证接口根据文件唯一hash值告诉前端是否上传过和已上传的分片列表。上传过就直接提示已上传。
// 判断该文件是否已上传
// uploadedList已上传的切片
const { shouldUpload, uploadedList } = await this.verifyUpload(this.fileData.name, this.fileHash)
if (!shouldUpload) {
this.progressDialog.visible = false
this.$message.success('skip upload:file upload success')
return
}
// 验证文件有没有上传过
async verifyUpload(filename, fileHash) {
const { data } = await this.request({
url: 'http://localhost:3003/verify',
headers: {
'content-type': 'application/json'
},
data: JSON.stringify({
filename,
fileHash
})
})
return JSON.parse(data)
}
# 断点续传
和文件秒传一样,根据验证接口返回是否上传过和已上传的分片列表,如果有已上传的列表前端把这些上传过的分片进行过滤,只上传那些未上传的,这样就实现了断点续传。
// 判断该文件是否已上传
// uploadedList已上传的切片
const { shouldUpload, uploadedList } = await this.verifyUpload(this.fileData.name, this.fileHash)
if (!shouldUpload) {
this.progressDialog.visible = false
this.$message.success('skip upload:file upload success')
return
}
// 创建上传列表
this.fileList = chunkList.map((item, index) => {
const hash = `${this.fileHash}-${index}` // 根据文件hash生成切片hash
const uploaded = uploadedList.includes(hash) // 是否已经上传
return {
fileHash: this.fileHash, // 唯一hash
size: item.file.size,
chunk: item.file,
hash,
name: hash,
index, // 当前索引
xhr: null, // 当前请求
status: uploaded ? 3 : 0, // 0 未上传 1上传中 2 取消上传 3 上传成功 4 上传失败
percent: uploaded ? 100 : 0, // 上传进度
loaded: 0, // 已上送大小(字节)
dateNow: 0, // 记录上传时间
time: 0, // 预估上传时间
}
})
以上就是大文件分片上传的大概流程,万变不离其中,其思想都是这一套,了解后其他不论是自己写上传组件,还是用云服务上传都差不多。
当前只提供了大文件上传的前端处理部分,后端暂时未提供,后续会使用node来模拟后端上传接口。
源码:
https://github.com/changzhengithub/upload-file (opens new window)
参考链接:
← 直播功能实现 单页面SEO优化方案 →